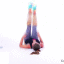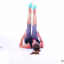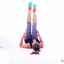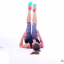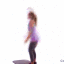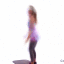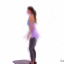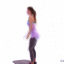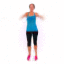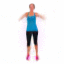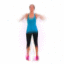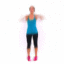Abstract
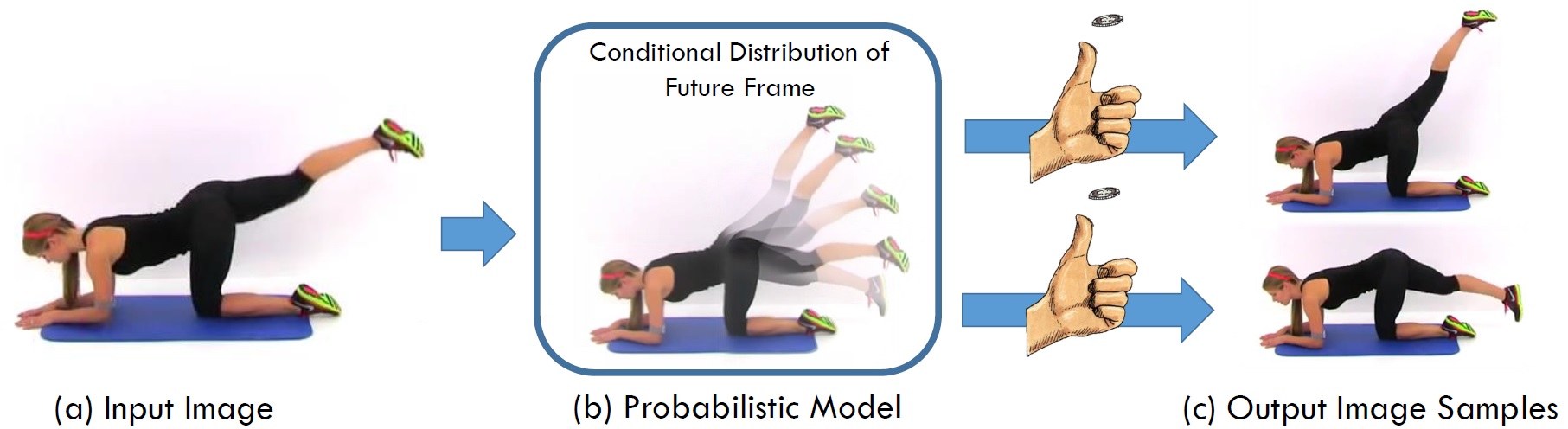
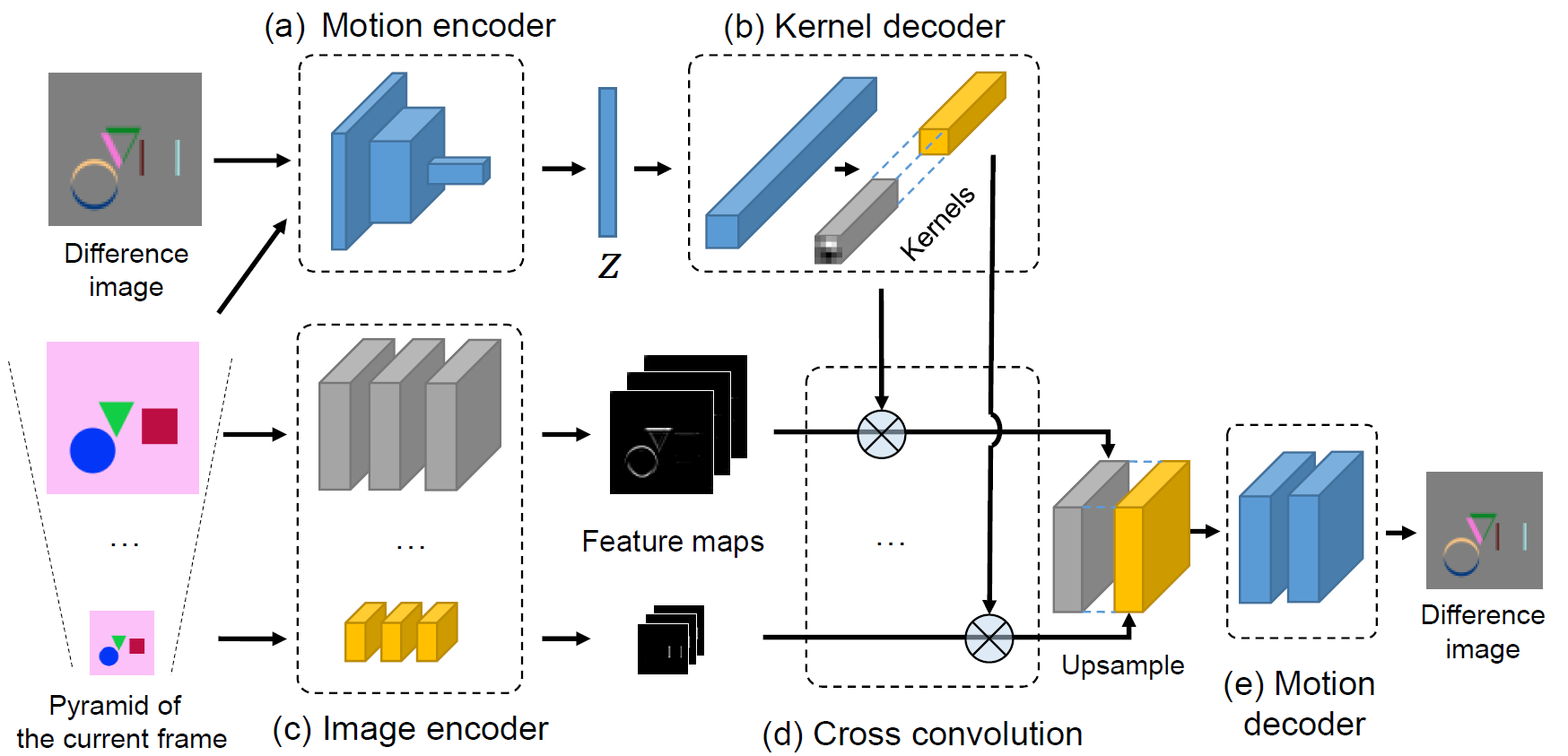
We study the problem of synthesizing a number of likely future frames from a single input image. In contrast to traditional methods that have tackled this problem in a deterministic or non-parametric way, we propose to model future frames in a probabilistic manner. Our probabilistic model makes it possible for us to sample and synthesize many possible future frames from a single input image. To synthesize realistic movement of objects, we propose a novel network structure, namely a Cross Convolutional Network; this network encodes image and motion information as feature maps and convolutional kernels, respectively. In experiments, our model performs well on synthetic data, such as 2D shapes and animated game sprites, and on real-world video frames. We present analyses of the learned network representations, showing it is implicitly learning a compact encoding of object appearance and motion. We also demonstrate a few of its applications, including visual analogy-making and video extrapolation.
@inproceedings{visualdynamics16,
author = {Xue, Tianfan and Wu, Jiajun and Bouman, Katherine L and Freeman, William T},
title = {Visual Dynamics: Probabilistic Future Frame Synthesis via Cross Convolutional Networks},
booktitle = {Advances In Neural Information Processing Systems},
year = {2016}
}
@article{visualdynamics,
author = {Xue, Tianfan and Wu, Jiajun and Bouman, Katherine L and Freeman, William T},
title = {Visual Dynamics: Stochastic Future Generation via Layered Cross Convolutional Networks},
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
volume = {41},
number = {9},
pages = {2236-2250},
year = {2019}
}
Downloads:
Acknowledgement
The authors thank
Yining Wang for helpful discussions. This work is supported by NSF Robust Intelligence 1212849, NSF Big Data 1447476, ONR MURI 6923196, Adobe, and Shell Research. The authors would also like to thank Nvidia for GPU donations.